Data blog












Create comparison report with command line client
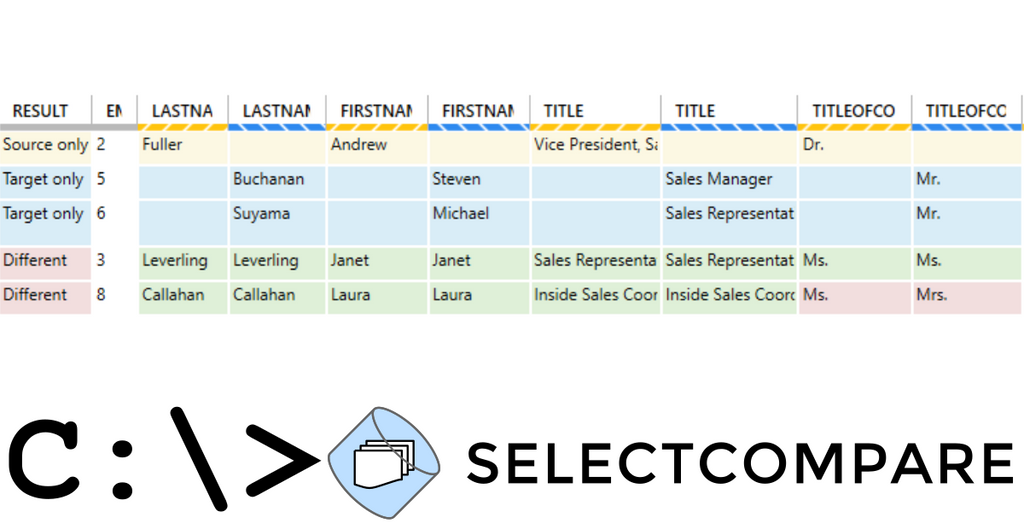
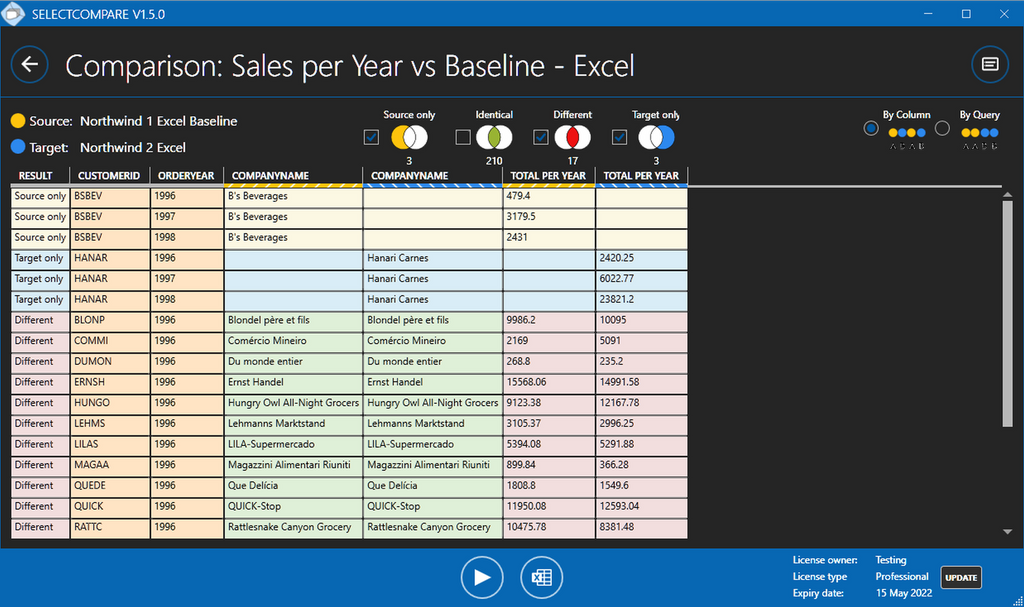
Following the previous post "Command line data comparison - how does it work?", I would like to show how to create a report containing the results of the data comparison.
The whole process is very simple. The command line client of SelectCompare offers you an easy way to export data to an Excel spreadsheet - the same format as the original version of SelectCompare creates.